Wie man einen KI-Agenten mit einer riesigen Legacy-Codebasis zum Arbeiten bringt, ohne Kontext oder Geld zu verlieren
Kommt dir das bekannt vor? Du bittest Claude oder ChatGPT, die Logik eines alten Projekts zu verstehen, und es beginnt zu "halluzinieren" oder verbraucht einfach sein gesamtes Token-Limit, indem es hunderte von Dateien mit einfachem grep durchsucht. Selbst moderne Agenten wie Claude Code verhalten sich oft wie blinde Kätzchen, wenn es um tiefe Verbindungen zwischen Services oder komplexe Aufrufketten geht.
Neulich bin ich auf das codebase-emory-mcp Repository gestoßen. Es ist ein MCP (Model Context Protocol) Server, der deinen Code in einen strukturierten Knowledge Graphen umwandelt. Anstatt rohen Text an das neuronale Netz zu verfüttern, baut das Tool eine Karte von Funktionen, Klassen und Abhängigkeiten auf, die die KI mit halbem Wort versteht.
Was ist falsch an normaler Suche
Wenn ein KI-Agent versucht, deinen Code zu verstehen, macht er es normalerweise auf die brutale Art. Er führt String-Suchen durch, öffnet Dateien eine nach der anderen und versucht, alles im Kopf zu behalten. Das Problem ist, dass das Kontextfenster nicht unendlich ist. Wenn das Projekt groß ist, vergisst der Agent schnell den Anfang der Aufrufkette oder beginnt, ähnliche Methoden in verschiedenen Modulen zu verwechseln.
Die Entwickler von DeusData behaupten beeindruckende Zahlen: Die Verwendung ihres Graphen reduziert den Tokenverbrauch um das 120-fache. Wo ein normaler Agent 400.000 Tokens verarbeiten muss, braucht dieses Tool nur drei- bis viertausend. Es geht nicht nur darum, Geld bei API-Aufrufen zu sparen – es geht in erster Linie um die Genauigkeit der Antworten.
Was dieses Tool kann
Das Projekt ist in "purem" C geschrieben und verwendet SQLite als Datenspeicher. Das gibt eine unglaubliche Geschwindigkeit. Das Indexieren des Linux-Kernels (das sind 28 Millionen Zeilen Code) dauert nur drei Minuten. Ein typisches Django- oder React-Projekt wird in ein paar Sekunden "geschluckt".
Hier sind ein paar Dinge, die mir aufgefallen sind:
- Architekturverständnis. Das Tool sieht nicht nur Text, sondern Struktur. Es unterscheidet API-Endpunkte, versteht, welche Funktion welche aufruft, und findet sogar "toten" Code, den niemand verwendet.
- Unterstützung für 66 Sprachen. Dank tree-sitter versteht das Tool fast alles – von Python und TypeScript bis Rust und COBOL. Außerdem kann es für C, C++ und Go Typen im LSP-Stil ableiten.
- Visualisierung. Es kommt mit einem (optionalen) 3D-Graph-Visualisierer. Du kannst dein Projekt buchstäblich im Browser bei
localhost:9749drehen und sehen, wie die Module verbunden sind. - Agent-Integration. Mit einem Befehl
installkonfiguriert sich das Tool für Claude Code, Zed, Aider und ein Dutzend anderer beliebter Tools.
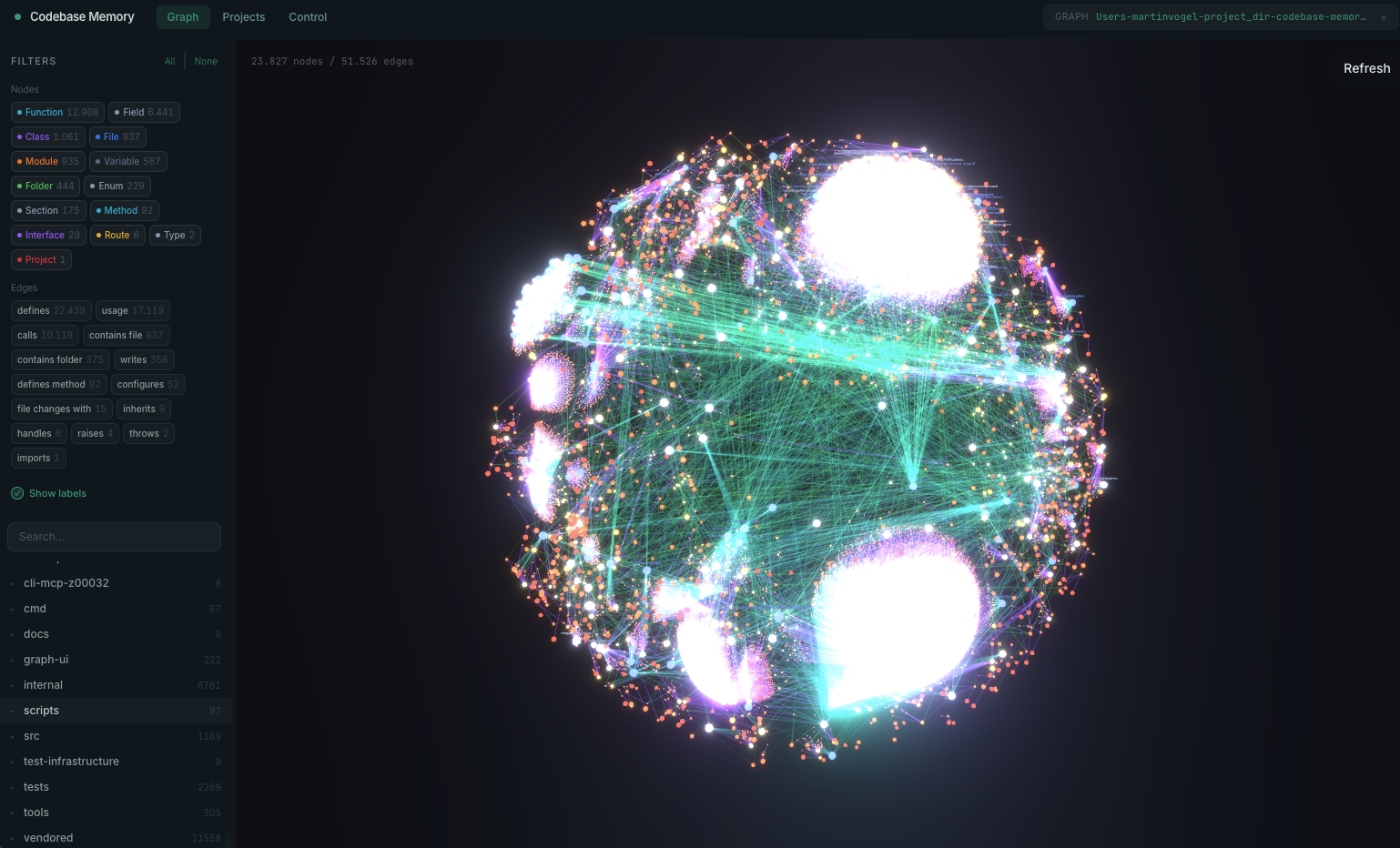
Der besagte 3D-Graph, den du im Browser drehen kannst
Wie es unter der Haube funktioniert
Interessanterweise haben die Autoren beschlossen, kein eigenes LLM einzubetten, um Queries in Datenbankbefehle zu übersetzen. Sie haben weise argumentiert: Da du bereits mit einem intelligenten Agenten sprichst (wie Claude 3.5 Sonnet), soll er die Übersetzung übernehmen.
Du fragst: "Wer ruft die Methode ProcessOrder auf?". Der Agent versteht die Absicht und ruft das Tool trace_call_path auf. Das Tool durchläuft den Graphen in Millisekunden und gibt eine strukturierte Antwort zurück. Als Ergebnis sieht die KI eine klare Kette, anstatt aus indirekten Hinweisen zu raten.
SQLite im WAL-Modus wird für die Speicherung verwendet, und die Daten werden mit dem LZ4-Algorithmus komprimiert. Dies ermöglicht es, den Index selbst sehr großer Projekte direkt im Speicher zu halten, ohne die Festplatte zu belasten.
Praktischer Nutzen für Entwickler
Der offensichtlichste Anwendungsfall ist das Onboarding in ein neues Projekt oder das Refactoring eines alten. Anstatt manuell Diagramme im Kopf zu erstellen, gibst du dem Agenten Zugriff auf codebase-memory-mcp.
Du kannst zum Beispiel fragen: "Finde alle Endpunkte, die UserID akzeptieren, aber keine Zugriffsrechte prüfen". Das Tool findet die Verbindungen zwischen HTTP-Routen und Validierungsmethoden, die eine normale Textsuche übersehen würde.
Ein weiteres cooles Feature ist detect_changes. Es analysiert deinen aktuellen Git-Diff und zeigt die "Blast Radius": welche Funktionen und Module deine Änderungen betreffen werden. Das ist großartige Absicherung vor dem Committen.
Wie du es ausprobieren kannst
Die Installation ist so einfach wie möglich – kein Docker oder zusätzliche Abhängigkeiten. Für macOS und Linux reicht ein Terminal-Befehl:
curl -fsSL https://raw.githubusercontent.com/DeusData/codebase-memory-mcp/main/install.sh | bash
Wenn du sofort Visualisierung willst, füge das Flag --ui hinzu. Nach der Installation startest du einfach deinen KI-Agenten neu und sagst ihm: "Indexiere dieses Projekt".
Lohnt es sich
Das Projekt sieht sehr vielversprechend aus. Was mir besonders gefällt, ist, dass es kein weiterer Cloud-Dienst ist, sondern ein lokales Tool. Dein gesamter Code bleibt auf deiner Maschine – keine Daten werden an externe Server zum Indexieren gesendet.
Natürlich gibt es Nuancen. Die Analysequalität für einige Sprachen wie Haskell ist noch niedriger als für Mainstream-Python oder Go. Aber die Liste der unterstützten Technologien und die Verarbeitungsgeschwindigkeit machen diese rauen Kanten mehr als wett.
Wenn du KI aktiv in deiner täglichen Entwicklung verwendest und das Gefühl hast, dass sie bei komplexen Aufgaben anfängt zu "stocken", könnte dieses Tool das fehlende Glied sein. Zumindest die Möglichkeit, dein Projekt als 3D-Graph zu sehen, ist definitiv zehn Minuten Installationszeit wert.
Ähnliche Projekte